안드로이드 NDK를 이용하여 MFC제작된 프로그램으로부터 한글을 수신받는 프로그램을 제작 중입니다.
MFC 프로그램은 제가 작성한 프로그램이 아니고 현재 소스도 가지고 있지 않아요.
있는 거라고는 유니코드라는 정보밖에 알 수가 없는 상황이고요;;
전송할 문자열 정보 :Unicode (Wide Char) String
계속 수신받은 문자들을 char배열에 넣어서 cpp에서 로그켓불러 출력해보니 다음과 같이 나타납니다..
원본 메시지 : 안녕하세요. 무엇을 도와드릴까요?
받은 메시지 : HUX8�. 4�D �@ܴL�?
막무가내로 NDK cpp코드에서 받은 문자배열을 env->NewStringUTF(받은 문자들); 로 바꿔서
자바로 전달 후 다음과 같은 내용의 자바코드 내 함수를 호출하여 인코딩 변경을 시도 했지만
public static void printRecvMSG(String msg) {
AppLog.logString("---------CALL JNI--------------------------");
AppLog.logString("MSG : "+msg);
String word = msg;
try {
AppLog.logString("utf-8 -> euc-kr : " + new String(word.getBytes("utf-8"), "euc-kr"));
AppLog.logString("utf-8 -> ksc5601 : " + new String(word.getBytes("utf-8"), "ksc5601"));
AppLog.logString("utf-8 -> x-windows-949 : " + new String(word.getBytes("utf-8"), "x-windows-949"));
AppLog.logString("utf-8 -> iso-8859-1 : " + new String(word.getBytes("utf-8"), "iso-8859-1"));
AppLog.logString("iso-8859-1 -> euc-kr : " + new String(word.getBytes("iso-8859-1"), "euc-kr"));
AppLog.logString("iso-8859-1 -> ksc5601 : " + new String(word.getBytes("iso-8859-1"), "ksc5601"));
AppLog.logString("iso-8859-1 -> x-windows-949 : " + new String(word.getBytes("iso-8859-1"), "x-windows-949"));
AppLog.logString("iso-8859-1 -> utf-8 : " + new String(word.getBytes("iso-8859-1"), "utf-8"));
AppLog.logString("euc-kr -> utf-8 : " + new String(word.getBytes("euc-kr"), "utf-8"));
AppLog.logString("euc-kr -> ksc5601 : " + new String(word.getBytes("euc-kr"), "ksc5601"));
AppLog.logString("euc-kr -> x-windows-949 : " + new String(word.getBytes("euc-kr"), "x-windows-949"));
AppLog.logString("euc-kr -> iso-8859-1 : " + new String(word.getBytes("euc-kr"), "iso-8859-1"));
AppLog.logString("ksc5601 -> euc-kr : " + new String(word.getBytes("ksc5601"), "euc-kr"));
AppLog.logString("ksc5601 -> utf-8 : " + new String(word.getBytes("ksc5601"), "utf-8"));
AppLog.logString("ksc5601 -> x-windows-949 : " + new String(word.getBytes("ksc5601"), "x-windows-949"));
AppLog.logString("ksc5601 -> iso-8859-1 : " + new String(word.getBytes("ksc5601"), "iso-8859-1"));
AppLog.logString("x-windows-949 -> euc-kr : " + new String(word.getBytes("x-windows-949"), "euc-kr"));
AppLog.logString("x-windows-949 -> utf-8 : " + new String(word.getBytes("x-windows-949"), "utf-8"));
AppLog.logString("x-windows-949 -> ksc5601 : " + new String(word.getBytes("x-windows-949"), "ksc5601"));
AppLog.logString("x-windows-949 -> iso-8859-1 : " + new String(word.getBytes("x-windows-949"), "iso-8859-1"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
AppLog.logString("--ERROR-----------------------------------------");
}
AppLog.logString("-------------------------------------------");
}
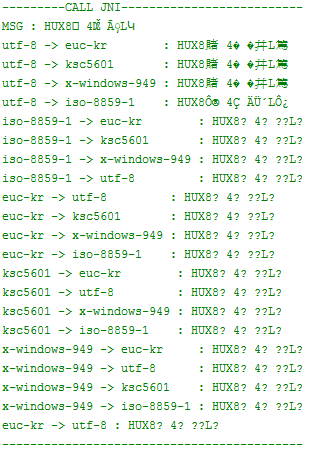
로그 결과는 요렇게 나오고 한글로 전혀 돌아가지 않고 4주 째 혼나고 있습니다.
cpp코드나 java 코드 어디서든 다시 한글로 돌릴 수 있는 방법이 없을까요?
어떤 언어 인코딩 차이여야 저렇게 깨지는지라도 누가 좀 알려주세요ㅠㅠ
부탁드립니다.

